-
대한민국 지하철데이터 가공해서 사용하기Language/Python 2025. 7. 1. 18:58
이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다.

여러 api를 모두 사용해 봤지만 지하철만 해도 여러 api를 믹스해서 사용해야한다 -_-;
서울쪽은 대부분 처리하였지만 지방 철도까지는 너무 힘들어서 단기간에 필요한 데이터를 얻으려면 공식사이트에서 제공하는 엑셀 파일을 가공해서 사용하는게 좋다는 판단을 내렸다.
장기적으로는 api가 좋겠지만 그건 나중일, 우린 시간이 금이니깐 여기까이만 하자!
1. 지하철 파일 내려받기
지하철 다운로드 메타 데이터를 내려받는다.
2. 지하철
2.1. 지하철 데이터 가공
- read_subway_data.py
데이터 정보를 확인해 본다.
import pandas as pd import os from pathlib import Path def read_subway_data(): """ 지하철 엑셀 파일을 읽어서 pandas DataFrame에 담고 총 개수를 출력하는 함수 """ # 파일 경로 설정 file_path = "/Users/deokjoonkang/dev/projects/gundam/claude/subway/전체_도시철도역사정보_20250417.xlsx" try: # 파일 존재 여부 확인 if not os.path.exists(file_path): print(f"파일을 찾을 수 없습니다: {file_path}") return None # 엑셀 파일 읽기 print("엑셀 파일을 읽는 중...") df = pd.read_excel(file_path) # 데이터 정보 출력 print(f"\n=== 지하철역 데이터 정보 ===") print(f"총 행 개수: {len(df):,}개") print(f"총 열 개수: {len(df.columns)}개") print(f"데이터 형태: {df.shape}") # 컬럼 정보 출력 print(f"\n=== 컬럼 정보 ===") for i, col in enumerate(df.columns, 1): print(f"{i}. {col}") # 처음 5행 미리보기 print(f"\n=== 처음 5행 미리보기 ===") print(df.head()) return df except Exception as e: print(f"파일 읽기 중 오류가 발생했습니다: {str(e)}") return None def get_subway_lines_dict(): """ 지하철 엑셀 파일을 읽어서 노선번호별 노선명을 딕셔너리로 반환하는 함수 """ # 파일 경로 설정 file_path = "/Users/deokjoonkang/dev/projects/gundam/claude/subway/전체_도시철도역사정보_20250417.xlsx" try: # 파일 존재 여부 확인 if not os.path.exists(file_path): print(f"파일을 찾을 수 없습니다: {file_path}") return None # 엑셀 파일 읽기 print("지하철 노선 정보를 읽는 중...") df = pd.read_excel(file_path) # 노선번호와 노선명 컬럼 찾기 line_number_col = None line_name_col = None # 컬럼명에서 노선번호와 노선명을 찾기 for col in df.columns: if col == '노선번호': line_number_col = col elif col == '노선명': line_name_col = col if line_number_col is None or line_name_col is None: print("노선번호 또는 노선명 컬럼을 찾을 수 없습니다.") print("사용 가능한 컬럼:") for i, col in enumerate(df.columns, 1): print(f"{i}. {col}") return None print(f"노선번호 컬럼: {line_number_col}") print(f"노선명 컬럼: {line_name_col}") # 노선번호와 노선명으로 중복 제거하여 딕셔너리 생성 lines_dict = {} # NaN 값 제거하고 중복 제거 clean_df = df[[line_number_col, line_name_col]].dropna() unique_lines = clean_df.drop_duplicates() for _, row in unique_lines.iterrows(): line_number = str(row[line_number_col]).strip() line_name = str(row[line_name_col]).strip() if line_number and line_name and line_number != 'nan' and line_name != 'nan': lines_dict[line_number] = line_name print(f"\n=== 노선번호별 노선명 딕셔너리 ===") print(f"총 {len(lines_dict)}개의 노선이 있습니다.") for line_number, line_name in sorted(lines_dict.items()): print(f"{line_number}: {line_name}") return lines_dict except Exception as e: print(f"노선 정보 추출 중 오류가 발생했습니다: {str(e)}") return None def get_subway_lines(): """ 프로그램에서 사용하기 위한 간단한 함수 노선번호별 노선명 딕셔너리를 반환합니다. """ return get_subway_lines_dict() if __name__ == "__main__": # 메인 실행 subway_df = read_subway_data() if subway_df is not None: print(f"\n✅ 성공적으로 지하철역 데이터를 읽었습니다!") print(f"📊 총 {len(subway_df):,}개의 지하철역 정보가 있습니다.") # 노선번호별 노선명 딕셔너리 생성 print(f"\n" + "="*50) lines_dict = get_subway_lines() if lines_dict: print(f"\n✅ 노선번호별 노선명 딕셔너리가 성공적으로 생성되었습니다!") print(f"📊 총 {len(lines_dict)}개의 노선 정보가 있습니다.") else: print("❌ 노선 정보 딕셔너리 생성에 실패했습니다.") else: print("❌ 데이터 읽기에 실패했습니다.")- subway_line_mapping.py
라인별 매핑 데이터들을 설정한다.
#!/usr/bin/env python3 # -*- coding: utf-8 -*- def get_line_mapping_dict(): """ 노선번호 코드별로 변경된 노선명을 매핑하는 딕셔너리 """ line_mapping = { 'I1101': '수도권1호선', # 기존 : 경인선 (1호선, 인천방향?) 'I1103': '수도권3호선', # 기존 : 3호선 'I1104': '수도권4호선', # 기존 : 4호선 'I11D1': '수도권신분당선', # 기존 : 신분당선 'I26K6': '동해선', # 기존 : 동해선 'I27K7': '대경선', # 기존 : 대경선 'I28A1': '공항선', # 기존 : 인천국제공항선 'I28K1': '수인분당', # 기존 : 수인선 'I4101': '수도권1호선', # 기존 : 1호선|경부선 (1호선, 수원방향?) 'I4102': '수도권1호선', # 기존 : 경원선 (1호선) 'I4103': '수도권4호선', # 기존 : 안산과천선 (4호선) 'I4104': '수도권4호선', # 기존 : 진접선 (4호선) 'I4105': '수인분당', # 기존 : 분당선 (수인분당) 'I4106': '수도권3호선', # 기존 : 일산선 (3호선) 'I4108': '수도권경의중앙선', # 기존 : 경의중앙선 'I41K2': '수도권경춘선', # 기존 : 경춘선 'I41K5': '수도권경강선', # 기존 : 경강선 'I41WS': '서해선', # 기존 : 서해선 'I4401': '수도권1호선', # 기존 : 경부선|장항선 (1호선) 'L11SL': '수도권신림선', # 기존 : 수도권 경량도시철도 신림선 (신림선) 'L11UI': '우이신설경전철', # 기존 : 우이신설선 'L2604': '부산4호선', # 기존 : 부산 경량도시철도 4호선 (부산4호선) 'L41E1': '수도권에버라인', # 기존 : 에버라인 'L41G1': '김포골드라인', # 기존 : 김포도시철도 'L41U1': '의정부경전철', # 기존 : 의정부 'L48B1': '부산김해경전철', # 기존 : 부산김해경전철 'S1102': '수도권2호선', # 기존 : 2호선 'S1105': '수도권5호선', # 기존 : 5호선 'S1106': '수도권6호선', # 기존 : 6호선 'S1107': '수도권7호선', # 기존 : 7호선|도시철도 7호선 (7호선) 'S1108': '수도권8호선', # 기존 : 8호선 'S1109': '수도권9호선', # 기존 : 수도권 도시철도 9호선 (9호선) 'S1121': '수도권2호선', # 기존 : 2호선 'S1122': '수도권2호선', # 기존 : 2호선 'S2601': '부산1호선', # 기존 : 부산 도시철도 1호선 'S2602': '부산2호선', # 기존 : 부산 도시철도 2호선 'S2603': '부산3호선', # 기존 : 부산 도시철도 3호선 'S2701': '대구1호선', # 기존 : 대구 도시철도 1호선 'S2702': '대구2호선', # 기존 : 대구 도시철도 2호선 'S2703': '대구3호선', # 기존 : 대구 도시철도 3호선 'S2801': '수도권인천1호선', # 기존 : 인천지하철 1호선 'S2802': '수도권인천2호선', # 기존 : 인천지하철 2호선 # TODO. 자기부상철도 제외 (사용안함) 'S28M1': '', # 기존 : 자기부상철도 'S2901': '광주1호선', # 기존 : 광주도시철도 1호선 'S3001': '대전1호선', # 기존 : 대전 도시철도 1호선 'S4108': '수도권8호선' # 기존 : 수도권 광역철도 8호선 } return line_mapping def get_line_short_mapping_dict(): """ 노선번호 코드별로 노선 단축명을 매핑하는 딕셔너리 """ line_short_mapping = { 'I1101': '1호선', # 기존 : 경인선 (1호선, 인천방향?) 'I1103': '3호선', # 기존 : 3호선 'I1104': '4호선', # 기존 : 4호선 'I11D1': '신분당선', # 기존 : 신분당선 'I26K6': '동해선', # 기존 : 동해선 'I27K7': '대경선', # 기존 : 대경선 'I28A1': '공항선', # 기존 : 인천국제공항선 'I28K1': '수인분당', # 기존 : 수인선 'I4101': '1호선', # 기존 : 1호선|경부선 (1호선, 수원방향?) 'I4102': '1호선', # 기존 : 경원선 (1호선) 'I4103': '4호선', # 기존 : 안산과천선 (4호선) 'I4104': '4호선', # 기존 : 진접선 (4호선) 'I4105': '수인분당', # 기존 : 분당선 (수인분당) 'I4106': '3호선', # 기존 : 일산선 (3호선) 'I4108': '경의중앙선', # 기존 : 경의중앙선 'I41K2': '경춘선', # 기존 : 경춘선 'I41K5': '경강선', # 기존 : 경강선 'I41WS': '서해선', # 기존 : 서해선 'I4401': '1호선', # 기존 : 경부선|장항선 (1호선) 'L11SL': '신림선', # 기존 : 수도권 경량도시철도 신림선 (신림선) 'L11UI': '우이신설선', # 기존 : 우이신설선 'L2604': '4호선', # 기존 : 부산 경량도시철도 4호선 (4호선) 'L41E1': '에버라인', # 기존 : 에버라인 'L41G1': '김포골드라인', # 기존 : 김포도시철도 'L41U1': '의정부경전철', # 기존 : 의정부 'L48B1': '부산김해경전철', # 기존 : 부산김해경전철 'S1102': '2호선', # 기존 : 2호선 'S1105': '5호선', # 기존 : 5호선 'S1106': '6호선', # 기존 : 6호선 'S1107': '7호선', # 기존 : 7호선|도시철도 7호선 (7호선) 'S1108': '8호선', # 기존 : 8호선 'S1109': '9호선', # 기존 : 수도권 도시철도 9호선 (9호선) 'S1121': '2호선', # 기존 : 2호선 'S1122': '2호선', # 기존 : 2호선 'S2601': '부산1호선', # 기존 : 부산 도시철도 1호선 'S2602': '부산2호선', # 기존 : 부산 도시철도 2호선 'S2603': '부산3호선', # 기존 : 부산 도시철도 3호선 'S2701': '대구1호선', # 기존 : 대구 도시철도 1호선 'S2702': '대구2호선', # 기존 : 대구 도시철도 2호선 'S2703': '대구3호선', # 기존 : 대구 도시철도 3호선 'S2801': '인천1호선', # 기존 : 인천지하철 1호선 'S2802': '인천2호선', # 기존 : 인천지하철 2호선 # TODO. 자기부상철도 제외 (사용안함) 'S28M1': '', # 기존 : 자기부상철도 'S2901': '광주1호선', # 기존 : 광주도시철도 1호선 'S3001': '대전1호선', # 기존 : 대전 도시철도 1호선 'S4108': '8호선' # 기존 : 수도권 광역철도 8호선 } return line_short_mapping def print_line_mapping_info(): """ 노선 매핑 정보를 출력하는 함수 """ line_mapping = get_line_mapping_dict() line_short_mapping = get_line_short_mapping_dict() print("🚇 노선번호 코드별 매핑 정보") print("=" * 60) print(f"총 {len(line_mapping)}개의 노선 매핑") print() for line_code in sorted(line_mapping.keys()): line_name = line_mapping[line_code] line_short = line_short_mapping[line_code] print(f"{line_code:8s} → {line_name:20s} (단축명: {line_short})") if __name__ == "__main__": print_line_mapping_info()- generate_subway_sql.py
insert 쿼리를 생성한다.
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import pandas as pd import os from datetime import datetime from subway_line_mapping import get_line_mapping_dict, get_line_short_mapping_dict def generate_subway_insert_sql(): """ 지하철 엑셀 파일을 읽어서 SUBWAY 테이블 INSERT SQL을 생성하는 함수 """ # 파일 경로 설정 file_path = "/Users/deokjoonkang/dev/projects/gundam/claude/subway/전체_도시철도역사정보_20250417.xlsx" try: # 파일 존재 여부 확인 if not os.path.exists(file_path): print(f"파일을 찾을 수 없습니다: {file_path}") return None # 엑셀 파일 읽기 print("지하철 데이터를 읽는 중...") df = pd.read_excel(file_path) # 노선 매핑 딕셔너리 가져오기 line_mapping = get_line_mapping_dict() line_short_mapping = get_line_short_mapping_dict() print(f"총 {len(df)}개의 지하철역 데이터를 처리합니다.") print(f"노선 매핑 딕셔너리: {len(line_mapping)}개 노선") # SQL 파일 생성 output_file = "data_migration/subway/subway_insert.sql" current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S") with open(output_file, 'w', encoding='utf-8') as f: # SQL 파일 헤더 작성 f.write("-- 지하철역 데이터 INSERT SQL\n") f.write(f"-- 생성일시: {current_time}\n") f.write(f"-- 총 {len(df)}개의 지하철역 데이터\n") f.write("-- 노선번호 코드별 매핑된 노선명 사용\n") f.write("-- FULL_NAME 형식: LINE_NAME\n\n") # INSERT 문 시작 f.write("INSERT INTO SUBWAY (PLACE_CODE, FULL_NAME, LINE_CODE, LINE, LINE_SHORT, NAME, LATITUDE, LONGITUDE, USE_YN, REG_DT) VALUES\n") # 각 행을 SQL INSERT 값으로 변환 sql_values = [] skipped_count = 0 for index, row in df.iterrows(): try: # 각 컬럼 데이터 추출 및 변환 place_code = str(row['역번호']).strip() if pd.notna(row['역번호']) else '' raw_full_name = str(row['역사명']).strip() if pd.notna(row['역사명']) else '' line_code = str(row['노선번호']).strip() if pd.notna(row['노선번호']) else '' # 노선번호 코드에 따른 노선명 매핑 if line_code in line_mapping: line = line_mapping[line_code] line_short = line_short_mapping[line_code] # 빈 값으로 설정된 노선은 제외 if not line or line.strip() == '': print(f"⚠️ 행 {index+1}: 제외된 노선번호 코드 '{line_code}' - 건너뜀") skipped_count += 1 continue else: print(f"⚠️ 행 {index+1}: 알 수 없는 노선번호 코드 '{line_code}' - 건너뜀") skipped_count += 1 continue # NAME 처리: 괄호 제거 후 "역" 추가 # 괄호가 포함된 경우 괄호 부분 제거 if '(' in raw_full_name and ')' in raw_full_name: # 괄호 시작 위치 찾기 bracket_start = raw_full_name.find('(') name_without_bracket = raw_full_name[:bracket_start].strip() else: name_without_bracket = raw_full_name # "역"이 없으면 "역" 추가 if name_without_bracket and not name_without_bracket.endswith('역'): name = name_without_bracket + '역' else: name = name_without_bracket # FULL_NAME 처리: LINE + '_' + NAME 형태 (NAME에 이미 역이 포함됨) full_name = f"{line}_{name}" # 위도/경도 처리 latitude = float(row['역위도']) if pd.notna(row['역위도']) else 0.0 longitude = float(row['역경도']) if pd.notna(row['역경도']) else 0.0 # 데이터 유효성 검사 if not place_code or not full_name or not line_code: print(f"⚠️ 행 {index+1}: 필수 데이터 누락 - 건너뜀") skipped_count += 1 continue if latitude == 0.0 and longitude == 0.0: print(f"⚠️ 행 {index+1}: 위도/경도 데이터 없음 - 건너뜀") skipped_count += 1 continue # SQL 값 생성 sql_value = f"('{place_code}', '{full_name}', '{line_code}', '{line}', '{line_short}', '{name}', {latitude}, {longitude}, 'Y', NOW())" sql_values.append(sql_value) if (index + 1) % 100 == 0: print(f"진행률: {index + 1}/{len(df)} ({((index + 1) / len(df) * 100):.1f}%)") except Exception as e: print(f"❌ 행 {index+1} 처리 중 오류: {str(e)}") skipped_count += 1 continue # SQL 값들을 파일에 작성 for i, sql_value in enumerate(sql_values): if i == len(sql_values) - 1: f.write(sql_value + ";\n") else: f.write(sql_value + ",\n") # SQL 파일 푸터 f.write(f"\n-- 총 {len(sql_values)}개의 INSERT 문이 생성되었습니다.\n") f.write(f"-- 제외된 데이터: {skipped_count}개\n") f.write(f"-- 생성 완료: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n") print(f"\n✅ SQL 파일이 성공적으로 생성되었습니다!") print(f"📁 파일명: {output_file}") print(f"📊 총 {len(sql_values)}개의 INSERT 문이 생성되었습니다.") print(f"📈 처리된 데이터: {len(sql_values)}/{len(df)} ({len(sql_values)/len(df)*100:.1f}%)") print(f"❌ 제외된 데이터: {skipped_count}개") return output_file except Exception as e: print(f"SQL 생성 중 오류가 발생했습니다: {str(e)}") return None def preview_sql_file(filename, lines=10): """ 생성된 SQL 파일의 미리보기를 출력하는 함수 """ try: with open(filename, 'r', encoding='utf-8') as f: content = f.readlines() print(f"\n📋 SQL 파일 미리보기 (처음 {lines}줄):") print("=" * 60) for i, line in enumerate(content[:lines]): print(f"{i+1:2d}: {line.rstrip()}") if len(content) > lines: print("...") print(f"총 {len(content)}줄") except Exception as e: print(f"파일 미리보기 중 오류: {str(e)}") if __name__ == "__main__": # SQL 파일 생성 sql_file = generate_subway_insert_sql() if sql_file: # 생성된 SQL 파일 미리보기 preview_sql_file(sql_file, 15) print(f"\n🎉 지하철역 데이터 INSERT SQL 생성이 완료되었습니다!") print(f"💡 생성된 파일을 데이터베이스에서 실행하세요.") else: print("❌ SQL 파일 생성에 실패했습니다.")2.2. 등록 쿼리 확인
등록쿼리가 생성되었다.
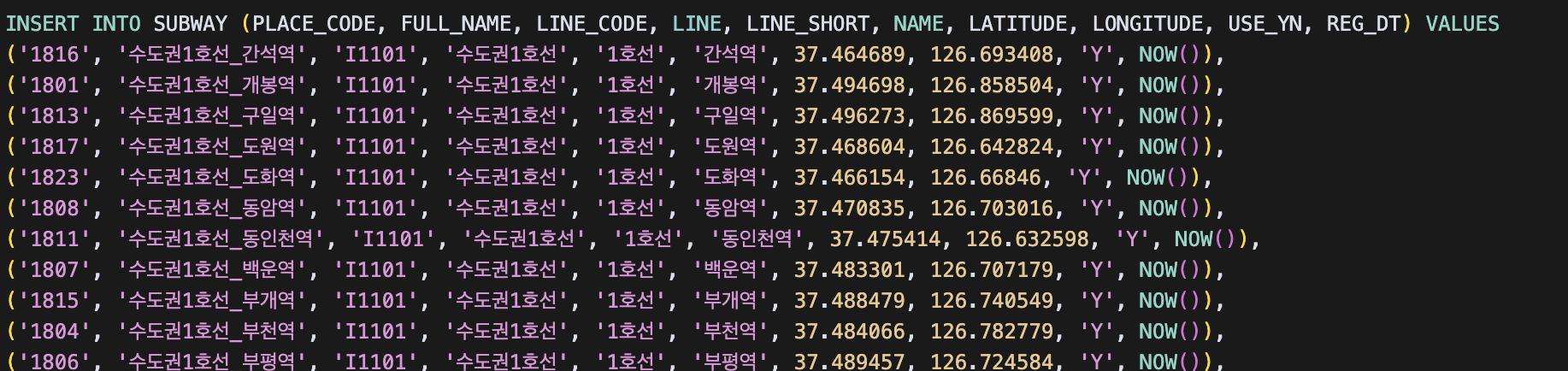
파일을 분석하거나 가공하는건 파이썬이 진짜 짱인것 같다!
'Language > Python' 카테고리의 다른 글
MacOS Python 설치 (대중적이고 버전관리 쉬운 방향) (0) 2026.01.15 대한민국 대학교데이터 가공해서 사용하기 (1) 2025.07.03 Python으로 MCP Server 만들기 (2) 2025.03.07 uv/uvx란 무엇이고 설치는? (0) 2025.03.07 selenium으로 크롤링하고 Slack에 메시지 전송 (2) 2024.11.24 이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다.